Cloudera with Openstack a Wordcount Example
Cloudera with Openstack a Wordcount Example
Introduction
I want to have a look to Cloudera without install in it, so I just a image for docker.
Also the most of the content (for MapReduced) comes from : Hadoop Platform and Application Framework por Universidad de California en San Diego: https://www.coursera.org/learn/hadoop/home/welcome. It is part of an assignment.
Set up the container
I have docker in another computer, I should communicate throught SSH.
ssh -i /home/raf/Documents/Cloud/rvf_keele_cloud.pem -L 9100:localhost:9100 ubuntu@10.8.3.12
To connect with HUE
localhost:9100
There is a container: https://hub.docker.com/r/cloudera/quickstart/
To set the image:
docker pull cloudera/quickstart
To run the image
docker run --hostname=quickstart.cloudera --privileged=true -t -i -p 9100:8888 -p 90:80 -p 7180:7180 -v /home/raf/Documents/docker-cloudera:/home/raf/Documents/docker-cloudera --name cloudera_wordcount cloudera/quickstart /usr/bin/docker-quickstart
-v /home/raf/Documents/docker-cloudera:/home/raf/Documents/docker-cloudera: I am linking one folder in my desktop with a folder inside the container. The first one is my desktop the second one is the container.
-p is for the ports the first por is mine the second one is the container.
You can see HUE in localhost:8888
Run Mapreduce wordcount
Go to the folder you want to work, for me cd home/raf/Documents/docker-cloudera.
Create Wordcount_mapper.py
Understanding the algorithm:
You just have to put then in form of <key,1>
Create code:
vim wordcount_mapper.py
An paste this:
#!/usr/bin/env python
| |
# the above just indicates to use python to intepret this file
| |
# ---------------------------------------------------------------
| |
# This mapper code will input a line of text and output <word, 1>
| |
#
| |
# ---------------------------------------------------------------
| |
import sys # a python module with system functions for this OS
| |
# ------------------------------------------------------------
| |
# this 'for loop' will set 'line' to an input line from system
| |
# standard input file
| |
# ------------------------------------------------------------
| |
for line in sys.stdin:
| |
# -----------------------------------
| |
# sys.stdin call 'sys' to read a line from standard input,
| |
# note that 'line' is a string object, ie variable, and it has methods that you can apply to it,
| |
# as in the next line
| |
# ---------------------------------
| |
line = line.strip() # strip is a method, ie function, associated
| |
# with string variable, it will strip
| |
# the carriage return (by default)
| |
keys = line.split() # split line at blanks (by default),
| |
# and return a list of keys
| |
for key in keys: # a for loop through the list of keys
| |
value = 1
| |
print('{0}\t{1}'.format(key, value)) # the {} is replaced by 0th,1st items in format list
| |
# also, note that the Hadoop default is 'tab' separates key from the value
|
Close vim saving the changes: :wq
Create Wordcount_reducer.py
Understanding the algorithm:
First off all you should notice that you are going to have as an input the output of all reducers combined, so something like this:
A 1
a 1
ago 1
Another 1
away 1
far 1
far 1
episode 1
galaxy 1
in 1
long 1
of 1
Star 1
time 1
Wars 1
Therefore you do not have to worry of taking the files from previous map results combined them and sorted. So can count the repetitions by comparing whith the previous element
Create code:
vim wordcount_reducer.py
An paste this:
#!/usr/bin/env python
| |
# ---------------------------------------------------------------
| |
# This reducer code will input a line of text and
| |
# output <word, total-count>
| |
# ---------------------------------------------------------------
| |
import sys
| |
last_key = None # initialize these variables
| |
running_total = 0
| |
# -----------------------------------
| |
# Loop thru file
| |
# --------------------------------
| |
for input_line in sys.stdin:
| |
input_line = input_line.strip()
| |
# --------------------------------
| |
# Get Next Word # --------------------------------
| |
this_key, value = input_line.split("\t", 1) # the Hadoop default is tab separates key value
| |
# the split command returns a list of strings, in this case into 2 variables
| |
value = int(value) # int() will convert a string to integer (this program does no error checking)
| |
# ---------------------------------
| |
# Key Check part
| |
# if this current key is same
| |
# as the last one Consolidate
| |
# otherwise Emit
| |
# ---------------------------------
| |
if last_key == this_key: # check if key has changed ('==' is
| |
# logical equalilty check
| |
running_total += value # add value to running total
| |
else:
| |
if last_key: # if this key that was just read in
| |
# is different, and the previous
| |
# (ie last) key is not empy,
| |
# then output
| |
# the previous <key running-count>
| |
print("{0}\t{1}".format(last_key, running_total))
| |
# hadoop expects tab(ie '\t')
| |
# separation
| |
running_total = value # reset values
| |
last_key = this_key
| |
if last_key == this_key:
| |
print("{0}\t{1}".format(last_key, running_total))
|
Make those files executables
chmod +x wordcount_mapper.py
chmod +x wordcount_reducer.py
Create some data
echo "A long time ago in a galaxy far far away" > testfile1
echo "Another episode of Star Wars" > testfile2
Move it to hadoop
Create my input file
hdfs dfs -mkdir /user/cloudera/input
Move the files
hdfs dfs -put /home/raf/Documents/docker-cloudera/testfile1 /user/cloudera/input
hdfs dfs -put /home/raf/Documents/docker-cloudera/testfile1 /user/cloudera/input
To check the folder in hadoop:
hadoop fs -ls /user/cloudera/input
Count the words. Run MapReduce
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-input /user/cloudera/input \
-output /user/cloudera/output_new \
-mapper /home/raf/Documents/docker-cloudera/wordcount_mapper.py \
-reducer /home/raf/Documents/docker-cloudera/wordcount_reducer.py
To check the results:
View the output directory:
hdfs dfs -ls /user/cloudera/output_new
Look at the files there and check out the contents, e.g.:
hdfs dfs -cat /user/cloudera/output_new/part-00000
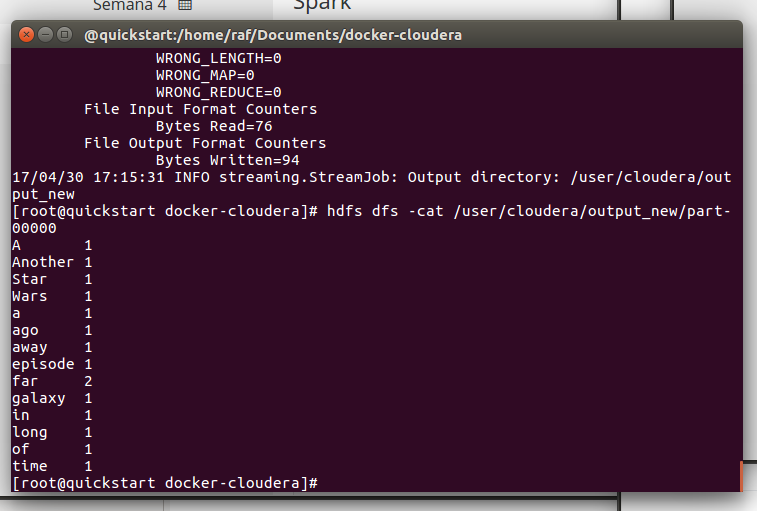
Changing Streaming options:
Try: hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar --help or see hadoop.apache.org/docs/r1.2.1/
Let’s change the number of reduce tasks to see its effects. Setting it to 0 will execute no reducer and only produce the map output. (Note the output directory is changed in the snippet below because Hadoop doesn’t like to overwrite output)
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-input /user/cloudera/input \
-output /user/cloudera/output_new_0 \
-mapper /home/raf/Documents/docker-cloudera/wordcount_mapper.py \
-reducer /home/raf/Documents/docker-cloudera/wordcount_reducer.py \
-numReduceTasks 0
To see the results:
hdfs dfs -cat /user/cloudera/output_new_0/part-00000

Try to notice the differences between the output when the reducers are run in Step 9, versus the output when there are no reducers and only the mapper is run in this step. The point of the task is to be aware of what the intermediate results look like. A successful submission will have words and counts that are not accumulated (which the reducer performs). Hopefully, this will help you get a sense of how data and tasks are split up in the map/reduce framework, and we will build upon that in the next lesson.
Collect this file:
- Move it outside hadoop
hadoop fs -get /user/cloudera/output_new_0/part-00000 INTERESTING MISTAKE!! THERE ARE 3 FILES 2 REDUCED AND 1 MAP TO ANSWER PROPERLY I SHOULD COMBINE ALL THE FILES: hdfs dfs -getmerge /user/cloudera/output_new_0/* wordcount_num0_output.txt
/home/raf/Documents/docker-cloudera/wordcount_num0_output.txt
THIS IS THE FINAL GOOD OUTPUT
A 1
long 1
time 1
ago 1
in 1
a 1
galaxy 1
far 1
far 1
away 1
Another 1
episode 1
of 1
Star 1
Wars 1
2) From the container to folder (it is not working what I did at the beginning from sync)
docker cp 13df07d2344dd8530fecf87af221833de8e3b018b217ca6e76f083f6d543d30f:/home/raf/Documents/docker-cloudera/wordcount_num0_output.txt /home/raf/Documents/docker-cloudera
wordcount_num0_output.txt
11. Change the number of reducers to 2 and answer the related quiz question #7 in the quiz for this Lesson.
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-input /user/cloudera/input \
-output /user/cloudera/output_new_2 \
-mapper /home/raf/Documents/docker-cloudera/wordcount_mapper.py \
-reducer /home/raf/Documents/docker-cloudera/wordcount_reducer.py \
-numReduceTasks 2
hdfs dfs -cat /user/cloudera/output_new_2/part-00000
References
- Hadoop Platform and Application Framework por Universidad de California en San Diego: https://www.coursera.org/learn/hadoop/home/welcome
Annex A Hadoop basic commands
To see all the commands of hadoop: (fs stands from file system)
hadoop fs
Listing all current files in this machine in hdfs
hadoop fs -ls /
To see in one folder:
hadoop fs -ls /user
To remove a folder
hadoop fs -rm -r /user/cloudera/output_new
To have access to the output files
hadoop fs -get /user/cloudera/output_new_0/part-00000 /home/raf/Documents/docker-cloudera/wordcount_num0_output.txt
hadoop fs -get /user/cloudera/output_new/part-00000 /home/raf/Documents/docker-cloudera/
hadoop fs -get /user/cloudera/output_new_2/part-00000 /home/raf/Documents/docker-cloudera/
References:
- https://www.youtube.com/watch?v=ZYQhHrq5kj8


Comentarios
Publicar un comentario